Seguridad y rendimiento
Imaginemos que queremos saber si dos cadenas son iguales, digamos: abcd y abdc.
Para ello, utilizaremos el algoritmo lógico: comparamos el primer carácter de la primera cadena con el primer carácter de la segunda cadena, vemos que son iguales así que comparamos el segundo carácter con el segundo carácter, vemos que son iguales y pasamos al tercero. Son diferentes, por tanto podemos dejar de comparar y concluir que ambas cadenas son diferentes.
¿Por qué enseñamos a comparar de esta forma? Porque el rendimiento es mejor: si, por ejemplo, las dos cadenas tuvieran doscientos caracteres sólo compararíamos los caracteres iguales y descartamos el resto: ahorramos tiempo.
¿Alguien ve algún problema hasta ahora?
Digamos, sólo por tener un punto de partida, que la comparación de un carácter tarda un milisegundo. Si el tercer carácter de la cadena ya es diferente y detenemos la comparación habremos utilizado tres milisegundos, si hubiésemos llegado hasta el final habríamos tardado doscientos milisegundos. Ya sabemos que son diferentes ¿para qué perder el tiempo?
¿Seguimos sin ver ningún problema?
Imaginemos que esas dos cadenas son contraseñas. Estamos comparando la cadena que ha introducido el usuario con la cadena que tenemos en la base de datos (o los hash, para el caso es lo mismo) y nos vamos a detener en el primer carácter que encontremos diferente.
Imaginemos también que alguien intenta averiguar la contraseña, en teoría podría introducir una contraseña cualquiera y medir el tiempo que tarda en responder el sistema con el mensaje Contraseña incorrecta.
Si por ejemplo, la contraseña buscada es bcde, podría comenzar probando la contraseña aaaaaa. Siguiendo con el ejemplo anterior, nos daría la respuesta al
milisegundo porque sólo se ha comparado un carácter. Ahora podríamos probar con baaaaa, esta vez tarda dos milisegundos, por lo tanto, el primer carácter es correcto
y ha comparado el segundo que es incorrecto. Probemos ahora con bbaaaaa, vuelve a tardar dos milisegundos así que probemos con bcaaaaa. ¡Bingo! tres milisegundos,
ya tenemos dos caracteres de nuestra contraseña.
A este tipo de ataque se les denomina ataques por tiempo. Se utilizaban mucho en los noventa en la época de los grandes servidores cuando todo era más predecible y evaluable y realmente la comparación de caracteres nos daba un tiempo medible. Se siguen utilizando aunque bastante menos y normalmente en sistemas donde el tiempo es predecible. Es muy raro utilizarlo contra un sitio web porque es bastante complicado saber cuál es el tiempo que ha tardado el procesador comparado con el tiempo de comunicación: mucho mayor y bastante aleatorio.
En cualquier caso, para evitarlo deberíamos intentar que el tiempo “evaluable” de esta comparación fuera exactamente igual independientemente de si hemos encontrado o no un carácter incorrecto.
Aunque pueda parecer lo contrario, el rendimiento cuando hablamos de seguridad puede llegar a ser contraproducente.
¿Quieren otro ejemplo? Veamos el código de inicio de sesión de una plantilla típica de inicio de sesión de ASP.Net:
[HttpPost("Login")]
public async Task<IActionResult> Login([FromBody] RequestLoginDto requestLoginDto)
{
Domain.ApplicationUser user = await _userManager.FindByNameAsync(requestLoginDto.Email);
if (user == null || !await _userManager.CheckPasswordAsync(user, requestLoginDto.Password))
return Unauthorized(new ResponseLoginDto
{
ErrorMessage = "Invalid Authentication"
}
);
else
{
Microsoft.AspNetCore.Identity.SignInResult signResult = await _signInManager.PasswordSignInAsync(user.UserName, requestLoginDto.Password, false, false);
if (signResult.Succeeded)
{
await _signInManager.SignInAsync(user, true);
return Ok(new ResponseLoginDto
{
IsAuthSuccessful = true,
Token = new JwtSecurityTokenHandler().WriteToken(GenerateTokenOptions(GetSigningCredentials(), GetClaims(user)))
}
);
}
else
return Unauthorized(new ResponseLoginDto
{
ErrorMessage = "Invalid Authentication"
}
);
}
}En este código, siguiendo todas las buenas prácticas, devolvemos el control en cuanto encontramos un error. Así en la línea 6, cuando no encontramos el usuario
en la base de datos, lanzamos un error. Sin siquiera comprobar la contraseña, fijáos en el or.
Y ahí tenemos algo medible, de hecho, el tiempo necesario para devolver el control en este caso es completamente diferente al caso en que encontramos un usuario aunque la contraseña sea incorrecta. Mucho más importante: este tiempo se puede medir independientemente de si estamos tras una conexión web:
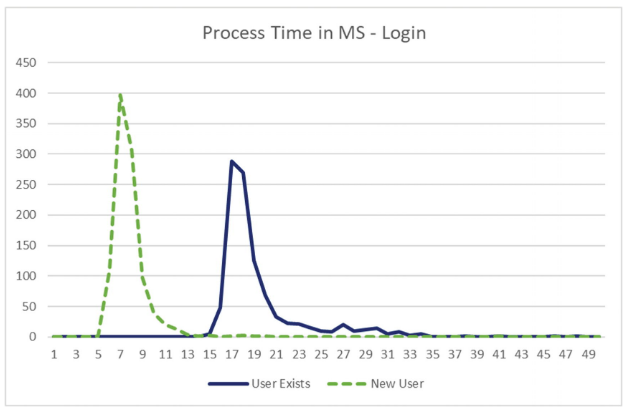
En el gráfico anterior, la línea verde es el tiempo que tarda el servicio en devolver el resultado cuando el usuario no existe, la línea azul es el tiempo empleado cuando el usuario existe. Una diferencia bastante apreciable.
Nota: la imagen está tomada del libro Advanced ASP.NET Core 3 Security de Scott Norberg (2.020). Totalmente recomendable.
Pero ¿qué podría conseguir un atacante con ésto?
Llevamos años diciendo que la forma correcta de mostrar un mensaje al usuario que no puede entrar al sistema es del tipo Su usuario o contraseña no son correctas en lugar de Su usuario no existe en el sistema o Su contraseña es incorrecta.
¿Por qué? En los mensajes de tipo Su contraseña es incorrecta le estamos diciendo al atacante que hemos encontrado el usuario pero que la contraseña no está bien. Por omisión, le estamos dando una información crucial: ese usuario existe en el sistema.
A partir de ese momento, el atacante puede intentar un ataque de fuerza bruta o si es un poco más inteligente un ataque de phising dirigido al usuario o
una búsqueda entre las bases de datos de usuarios y contraseñas que pululan por Internet por si el usuario ha reutilizado la clave o intentarlo
con la contraseña 123456 (por probar, nada más).
El caso es que cuando nuestro inicio de sesión tarda más tiempo en responder con los usuarios correctos que con los incorrectos, tenemos el mismo resultado que con el mensaje Su contraseña es incorrecta, le estamos dando al atacante información de cuáles son los usuarios de nuestro sistema. El atacante simplemente tiene que ir probando usuarios hasta que alguno de ellos tarde más tiempo en responder, en ese momento ya tendrá un usuario válido y podrá comenzar a atacarlo.
¿Cómo solucionamos ésto?
Pues en contra de todo lo que nos han enseñado a los programadores, en este caso debemos primar la seguridad sobre el rendimiento de forma que un usuario correcto tarde
el mismo tiempo en responder que un usuario incorrecto. De hecho, si tenemos que meter una instrucción Delay para que siempre tarden el mismo tiempo, hagámoslo. ¿Realmente
nos importa que el inicio de sesión tarde un segundo en lugar de tres?
Puede no parecer lógico pero en ciertos casos y por seguridad utilizamos algoritmos desarrollados específicamente para ser lentos. Sí, no me he equivocado: diseñados para ser lentos y a pesar de existir otros mucho más rápidos. En ASP.Net también, por cierto.
Uno de estos algoritmos se usa para almacenar los hash de las contraseñas en ASP.Net Identity. En concreto HMAC-SHA256 que por si fuera poco, se ejecuta 10.000 veces antes de grabar / comprobar una contraseña (y según van evolucionando los procesadores, quizá sería recomendable que se ejecutara más veces).
¿Por qué? Una de las formas que utiliza un atacante para descrifrar las claves a partir de cadenas Hash es con tablas rainbow. Con este tipo de algoritmos lo que intentamos precisamente es que generar este tipo de tablas sea lo más lento y costoso posible.
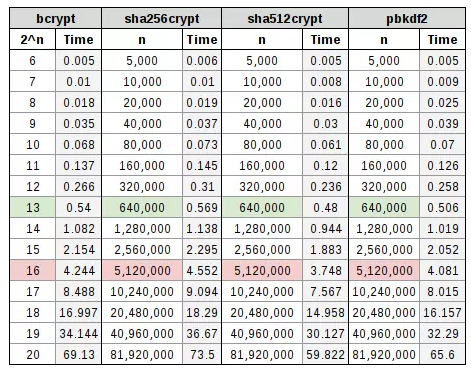
Nota: HMAC-SHA256 no es el único algoritmo lento que existe, los hay incluso más lentos:
Y eso es todo por hoy, simplemente recordemos dos cosas: que para la seguridad de nuestros sistemas en algunos casos el rendimiento es lo de menos y que no podemos confiar totalmente en las plantillas de ASP.Net.