Generación de informes - 3
Pues siguiendo con nuestra serie de artículos para la generación de informes, hoy vamos a dejar un poco la teoría y vamos a comenzar a plantear una librería que, en la medida de lo posible, nos permita crear mediante código informes complejos.
Por centrar la idea, en el artículo anterior, planteamos una serie de consultas SQL que en teoría nos facilitaban la solución del problema:
WITH CalendarCte AS
(SELECT Id, Date
FROM Dim.Calendar
WHERE Date BETWEEN '2022-01-01' AND '2022-12-31'
),
StoresCte AS
(SELECT Stores.Id AS StoreId, Stores.Name AS StoreName, Cities.Name AS City
FROM Dim.Stores INNER JOIN Dim.Cities
ON Stores.CityId = Cities.Id
AND Cities.Name = 'Madrid'
),
ProductsCte AS
(SELECT Products.Id AS ProductId, Products.Name AS ProductName
FROM Dim.Products
)
SELECT StoresCte.StoreName, ProductsCte.ProductName, CalendarCte.Date,
SUM(Sales.Quantity) AS Quantity, SUM(Sales.Price) AS Price
FROM Fact.Sales INNER JOIN CalendarCte
ON Sales.CalendarId = CalendarCte.Id
INNER JOIN StoresCte
ON Sales.StoreId = StoresCte.StoreId
INNER JOIN ProductsCte
ON Sales.ProductId = ProductsCte.ProductId
GROUP BY StoresCte.StoreName, ProductsCte.ProductName, CalendarCte.DateY hablamos de que la solución debía basarse en metadatos sobre el esquema de nuestra base de datos que nos facilitaran la creación de estas sentencias.
De este modo, la librería debería generar una instrucción SQL ejecutable que después podemos lanzar sobre la base de datos para obtener
un IDataReader que podamos utilizar para mostrar el informe en pantalla o para generar un JSON que podamos enviar al
frontend o para generar archivos CSV, Excel, parquet… es decir, algo que podamos consumir.
Para ello vamos a necesitar como entrada a nuestra librería cuatro elementos:
- El esquema físico de la base de datos.
- El esquema lógico de dimensiones y hechos.
- La solicitud del usuario, es decir, los campos de dimensiones y hechos que pretende obtener así como los filtros a aplicar.
- Un informe normalizado que podamos interpretar y a partir del cual generemos nuestra SQL.
Pretendo además que esa SQL sea independiente de la aplicación de base de datos que vamos a utilizar para que podamos generar el comando sin ligarnos demasiado a la implantación final.
Esquema físico
Como os podéis imaginar, el esquema físico es la representación del esquema de la base de datos.
De este esquema lo que realmente necesitamos son las tablas y vistas y sus campos.
De los campos nos interesan, aparte de su nombre, su tipo, longitud, si conforma una clave primaria, si admite nulos, etc…
Podríamos recoger también las claves foráneas, pero vamos a dejar las relaciones al esquema lógico. Esto nos permite tratar con bases de datos que no implementen este tipo de estructuras como las basadas en archivos (sí DuckDb, estoy mirándote a ti).
La estructura de entidades iniciales del esqumea físico de nuestra librería tendrá más o menos este aspecto:
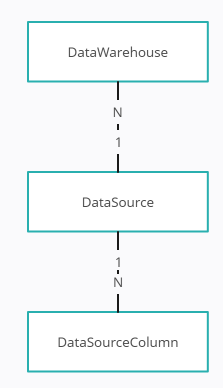
En este diagrama, la clase DataWarehouse va a ser nuestra clase raíz: agrupa nuestras entidades tanto del esquema físico
como el lógico.
Para el esquema físico, un DataWarehouse puede tener varios DataSource u orígenes de datos (que pueden ser tantos tablas
como vistas o incluso consultas SQL adicionales). Cada uno de estos orígenes de datos, por supuesto, tendrá columnas (DataSourceColumn).
A estas entidades del esquema físico, le vamos a añadir propiedades para definir una primera capa de metadatos sobre las tablas / vistas y campos. Esta capa de metadatos nos va a identificar:
- Los campos ocultos: es decir, aquellos campos que no deseamos que se muestren al usuario (aunque sí pueden aparecer internamente en las consultas como los identificadores).
- El nombre de tablas y campos que se le van a presentar al usuario. Por ejemplo, a la tabla
OrderLinela vamos a asociar el nombreOrder line, al campoProductCodele vamos a asociar el nombreCode… (la librería en este momento no está preparada para tratar con traducciones, pero con todo lo que nos queda por delante no vamos a preocuparnos ahora por ello). - Las descripciones de los campos y tablas para darle información adicional al usuario.
Esa información que vamos a añadir al esquema físico podría haberla dejado en entidades adicionales en el esquema lógico, pero por sencillez, he añadido propiedades a las propias entidades de tablas y campos del esquema físico.
Esquema lógico
El esquema lógico, por su parte, es quien nos identifica las dimensiones y sus relaciones, necesario para generar los informes a partir del esquema físico.
El diagrama de entidades de este esquema, tendría este aspecto:
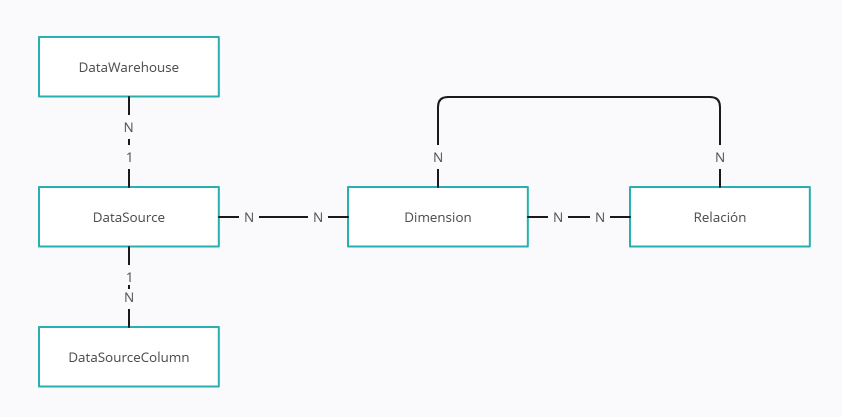
Así nuestra entidad Dimension va a ser una entidad sobre un origen de datos que puede tener dimensiones asociadas.
Las dimensiones, como decíamos pueden tener dimensiones asociadas o hija, por ejemplo, la dimensión Stores va a tener
una subdimensión llamada Cities.
Estas subdimensiones pueden asociarse a otras dimensiones, por ejemplo, podríamos tener
esa misma subdimensión Cities asociada a nuestra dimensión Employees.
Para mantener esta estructura debemos definir las relaciones entre las dimensiones. Una relación entre dimensiones puede ser tanto por uno como por varios campos.
Definición de informes
Con la definición del esquema físico y el lógico ya tenemos una base para la generación de SQL sobre las dimensiones definidas. De
hecho podríamos hacer consultas básicas con agrupaciones, pero para intentar cumplir con todos nuestros requisitos vamos a definir
una nueva entidad Reports:
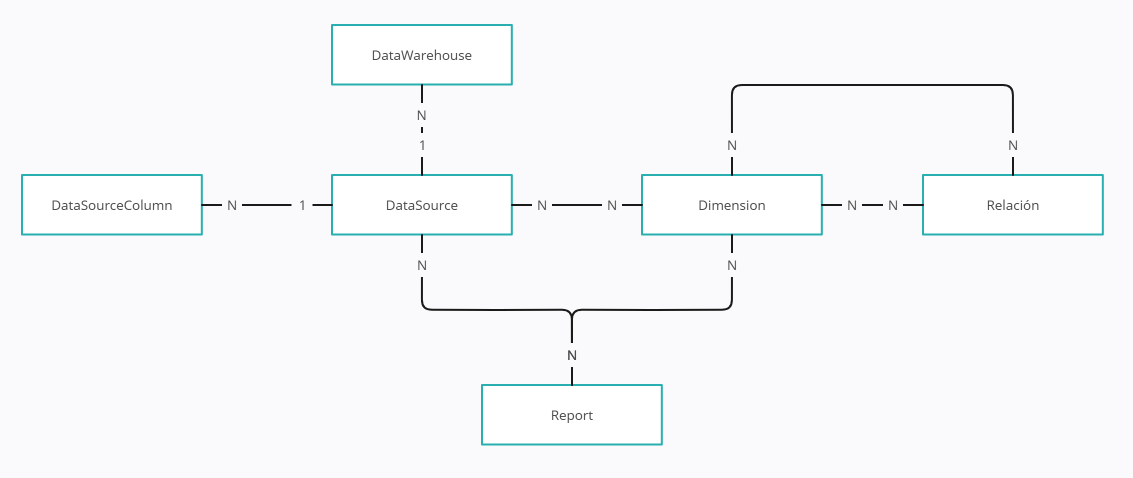
Esta entidad asocia una definición de informe con los orígenes de datos (tablas Fact) y las dimensiones.
Estos informes, van a formarse a partir de bloques. Podemos entender estos bloques como las cláusulas WITH que hemos visto en los comandos
utilizados como ejemplo, pero vamos a tener diferentes tipos de bloques para dar la capacidad al generador de tomar ciertas decisiones:
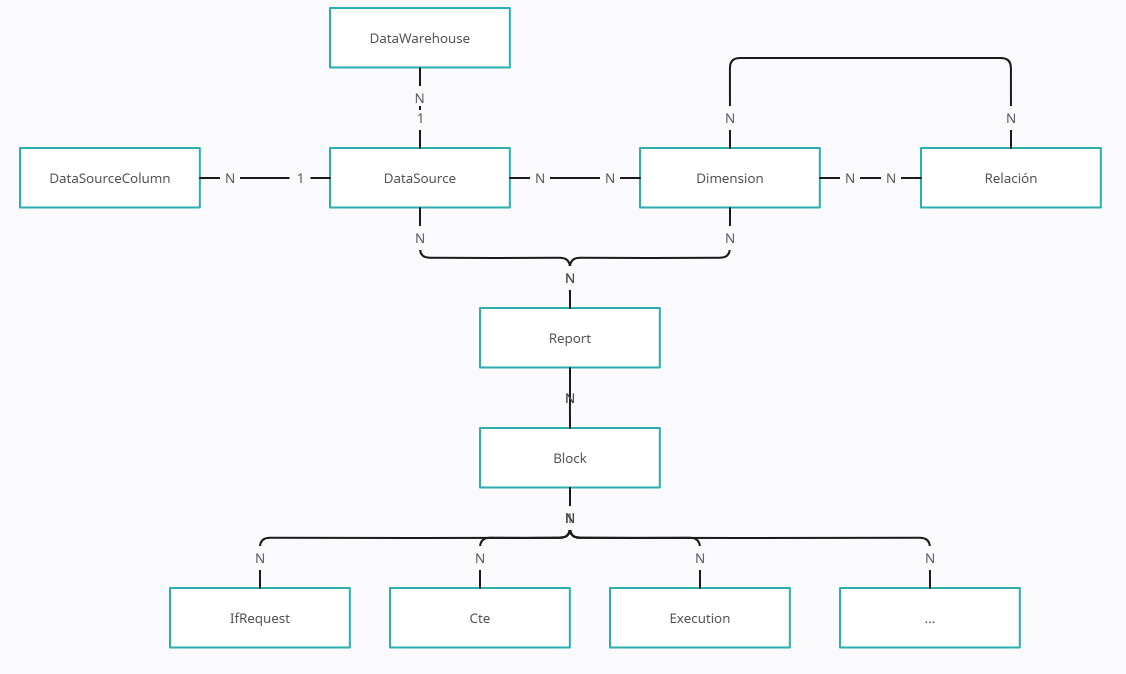
Por ejemplo, tenemos un bloque IfRequest para decidir qué pasa en nuestro informe si se ha solicitado (o no) una dimensión, bloques
Execute para ejecutar comandos de SQL (por ejemplo para crear una tabla temporal), bloques CTE para crear una cláusula WITH y
otros que iremos viendo en el futuro al ver ejemplos de uso.
Generador
Por supuesto, con todas estas entidades que conforman nuestra definición el generador es la parte de la librería que recoge esas definiciones, las mezcla con la solicitud del usuario (las entidades / campos que desea ver / filtrar) y genera una cadena SQL válida que podemos utilizar para consultar nuestra base de datos.
Conclusión
En este punto ya hemos definido nuestras entidades y cómo debe funcionar nuestra librería, en el siguiente artículo, veremos un ejemplo básico de cómo funciona y cómo se definen estos informes.